在中国AI公司的影响下,OpenAI 不得不公开O系列强化学习的秘密。近日,OpenAI发布了关于推理模型在竞技编程中应用的研究论文报告《Competitive Programming with Large Reasoning Models》,文中放出了OpenAI三个推理模型:o1、o1-ioi、o3在IOI和CodeForces(全球知名在线编程竞赛)中的成绩。
论文显示,在IOI 2024中,o3在严格规则下拿到395.64分,达成金牌成就,并且在CodeForces上的表现与人类精英选手相当。论文中特别提到,中国的DeepSeek-R1和Kimik1.5通过独立研究显示,利用思维链学习方法,可显著提升模型在数学解题与编程挑战中的综合表现。R1、k1.5是DeepSeek和Kimi在1月20日同时发布的新型推理模型。

该论文通过强化学习训练的大型语言模型在复杂编码和推理任务上的性能提升,比较了通用推理模型与针对特定领域优化的系统在竞技编程中的表现。研究结果表明,增加强化学习训练计算和测试时计算可显著提升模型性能,使其接近世界顶尖人类选手,这些模型将在科学、编码、数学等领域的AI应用中解锁新的应用体验。
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
上一篇:
资讯频道 2025-02-17 14:54

热点 2025-02-17 14:23
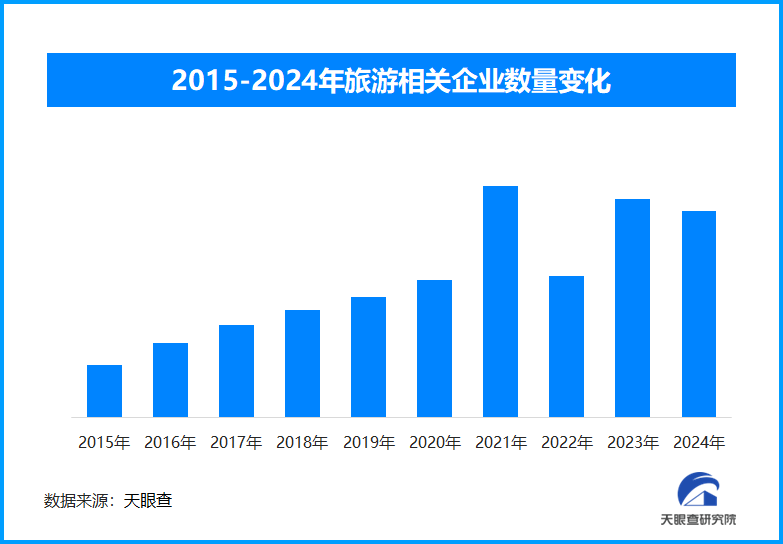
资讯频道 2025-02-17 13:34

资讯频道 2025-02-17 11:25
资讯频道 2025-02-17 11:24