作者:石玉阳,花名:Thorne, Flink-CDC Contributor,人力家资深数据工程师
仁励家网络科技(杭州)有限公司 简称“人力家”成立于2018 年,由钉钉与人力窝共同投资成立,是一家技术领先的人力资源数字化科技公司。
基于中国企业协同办公占有率排名第一的钉钉平台,提供一体化人力资源数字化解决方案和一站式人力资源管理服务,加速对中国企业人力资本服务的数字化赋能,实现人力资本管理的新工作方式,公司的使命愿景是 “普惠人力” “让HR进入数智化时代”。

在早期,人力家的内部数据仓库主要依托于MaxCompute这一强大的数据仓库软件进行数据处理与分析和DataWorks作为一站式数据开发平台,其中DataWorks的数据集成作为ETL软件,实时计算采用Flink VVR(Ververica Runtime) 作为计算引擎,离线/实时计算涵盖了财务、运营、APP、CRM、GTM、CS等多个业务域。随着对实时数据分析需求的日益增长,早期数仓存在一些弊端。包括:数据割裂(同一份数据可能存储在不同地方)、数据新鲜度低(T+1)、数据修复难度大/成本大、数据格式不够开放等问题频发。
随着新业务线的扩展,原有的大数据技术栈已经不能满足新产品睿人事(HCM)对OLAP极速分析的需求,公司需要一个能承载极速分析软件的外部客户的实时数仓,最终StarRocks凭借其MPP架构+Pipeline引擎+CBO优化器+Lakehouse架构的优秀表现被采纳。使用StarRocks来构建实时数仓帮助用户加速OLAP和复杂业务逻辑的构建,其中使用view table 建模,异步物化视图、生成列来加速OlAP查询。
经过近一年的不懈努力,我们公司已经构建了一个具备可持续性、可扩展性和灵活性的湖仓系统,为未来数据技术的发展奠定了坚实的基础。
首先,我们的湖仓系统采用了开放的数据格式,这使得数据不再受制于特定的计算引擎或云服务提供商。这种开放性为用户提供了极大的自由度,可以根据实际需求灵活选择最适合的计算工具和技术栈。例如,无论是Apache Spark、Flink还是StarRocks,都可以无缝地与我们的湖仓系统集成,从而实现高效的数据处理和分析。
其次,该湖仓架构支持多种计算模式之间的平滑切换。批处理、流处理以及增量计算等不同类型的计算任务可以在同一平台上进行,无需额外的迁移成本。这种多模式计算的支持极大地提高了系统的适应性和效率。例如,在面对大规模历史数据分析时,我们可以采用批处理模式;而在需要实时响应业务变化的情况下,则可以快速切换至流处理模式。此外,对于那些只需对新增数据进行处理的场景,增量计算模式则能够显著提升性能并减少资源消耗。

在探索湖仓架构的过程中,我们遇到了一些挑战。市场上存在多种不同的湖仓解决方案,尽管它们都声称能够提供“一体化”的体验,但实际上由于标准不一、术语混乱等因素,导致不同产品之间难以实现无缝集成。例如:
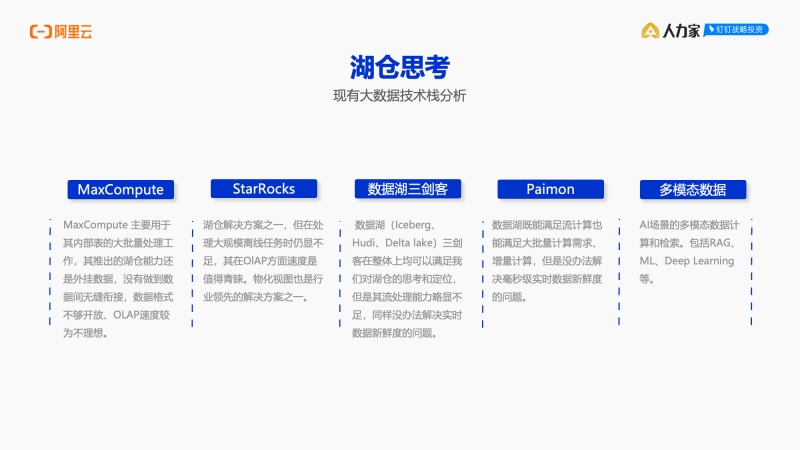
● MaxCompute 主要用于其内部表的大批量处理工作,其推出的湖仓能力还是外挂数据,没有做到数据间无缝衔接,数据格式不够开放和云厂商强绑定,OLAP速度较为不理想。
● StarRocks 虽然标榜为湖仓解决方案之一,但在处理大规模离线任务时仍显不足。
● 数据湖(Iceberg、Hudi、Delta lake)三剑客在整体上均可以满足我们对湖仓的思考和定位,但是其流处理能力略显不足。
● Paimon数据湖既能满足流计算也能满足批量计算需求,但是没办法解决实时数据新鲜度的问题。
● 多模态数据:AI场景的多模态数据计算和检索。
当前,大数据技术领域呈现出百花齐放的态势,这为用户在选择合适的工具和技术栈时带来了挑战。从行业实践来看,Apache Spark已成为批处理的事实标准,而Apache Flink则是流计算的事实标准;至于数据湖解决方案,Apache Iceberg正逐渐成为业界共识的选择之一。此外,随着人工智能(AI)计算需求的增长,向量检索与机器学习(ML)等领域也日益受到重视。
对于终端用户而言,依赖单一计算引擎并不符合实际需求。因此,构建一个能够支持多种计算引擎同时工作的生态系统显得尤为重要。关键在于实现存储层的数据格式标准化,确保不同类型的计算任务均可直接访问相同的数据源,而无需经历复杂的转换过程。换句话说,就是要打破数据与特定处理框架之间的绑定关系,采用开放且兼容性强的数据存储格式,使得无论何种计算引擎都能够轻松地根据既定规范读取并处理这些信息。
在构建开放数据湖的过程中,我们旨在打破数据孤岛,确保数据不被绑定于单一计算引擎,同时减少存储成本与使用成本。经过对Paimon、Iceberg、Hudi及Delta Lake等方案的深入调研后,基于以下几点考量:
1. 批处理和流处理能力:能同时满足批计算和流计算的场景。
2. 支持多样化计算模式:要求能够无缝支持流式与批处理计算,包括但不限于部分列更新、聚合表、索引等功能。
3. 生态兼容性:高度集成Flink、Spark、StarRocks等主流计算框架。
4. 社区活跃度:活跃的开发者社区、快速响应问题并持续创新的能力。
5. 数据新鲜度:可以和Fluss结合,弥补数据新鲜度的不足。
6. 多模态数据:可以支持多模态数据检索和计算。

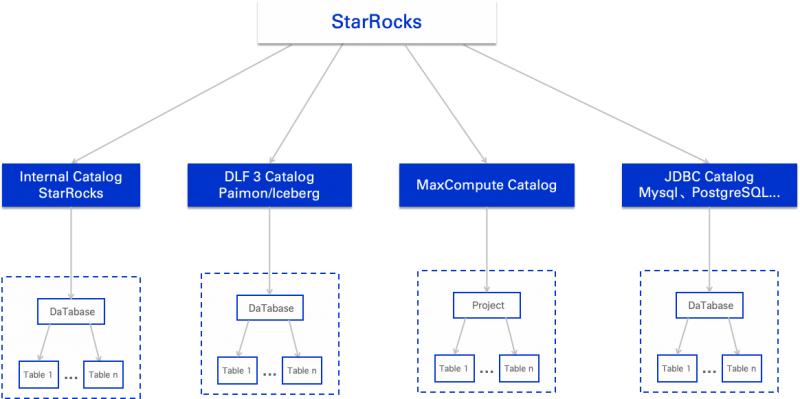
综上所述,基于阿里云OpenLake解决方案,最终决定采用Paimon作为核心数据湖技术,Fluss作为弥补Paimon数据新鲜度不足的前置处理,并通过阿里云提供的全托管Serverless服务形式部署,即商业版DLF(集成了Paimon、元数据管理和serverless架构、鉴权)。这一架构不仅满足了项目对于灵活性、性能和安全性方面的需求,还充分利用了云计算的优势来降低运维复杂度。
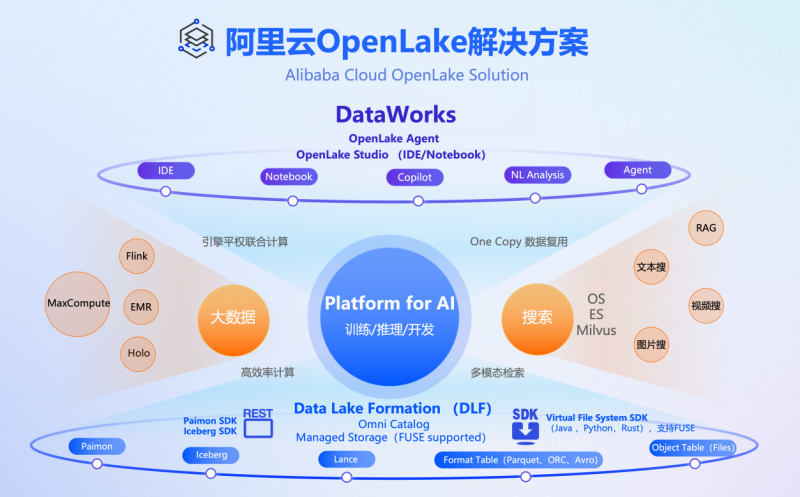
图片参考:阿里云OpenLake解决方案
我们舍弃了内部数仓中之前ETL作业,直接在数据标准层(dwd)直读DLF中的数据,得益于MaxCompute支撑的三层数据访问模型,我们仅需要轻微的改动,直接可以替换之前ODS层的数据。

MaxCompute中上层表的加工、计算逻辑不变,对于需要存入数据湖的数据直接写入Paimon中,供Flink、Starocks查询计算,如果用户使用的是Apache Spark,这里同样可以做到可替换成Apache Spark作为批计算引擎。
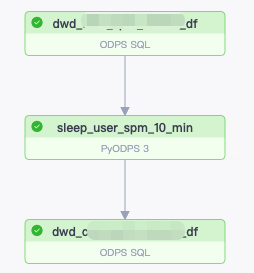
我们一直需要Agg Table的能力,以显著降低周期累计表的数据计算成本。尽管MaxCompute目前尚不支持这一功能,但我们已将此能力迁移到数据湖Paimon中,并成功将高成本的埋点周期累计表费用降低了70%。对于周期累积表,采用Paimon后,每日T+1计算仅需处理增量数据,而无需像在MaxCompute中那样全量合并历史与新增数据来求取事件事实的最大、最小值(如时间)。在Maxcompute中,只需将新产生的数据插入DLF,由其后台自动完成合并工作,但存在约1至10分钟的延迟。鉴于无法准确得知DLF完成数据合并的具体时刻,我们在Dataworks里增设了一个Python节点,设定该节点休眠10分钟后才启动下游任务调度,确保既不影响整体流程又能获取到最新的Agg Table的数据。

LakeHouse架构无疑是当前大数据的发展和趋势,通过LakeHouse架构我们可以无缝集成多Source数据,不让数据强行绑定在单一计算引擎上,解决过去无法从单一的产品中快速解放出来,减少ETL过程和数据复杂度,在不改变原有业务的情况下, 进行极速分析。
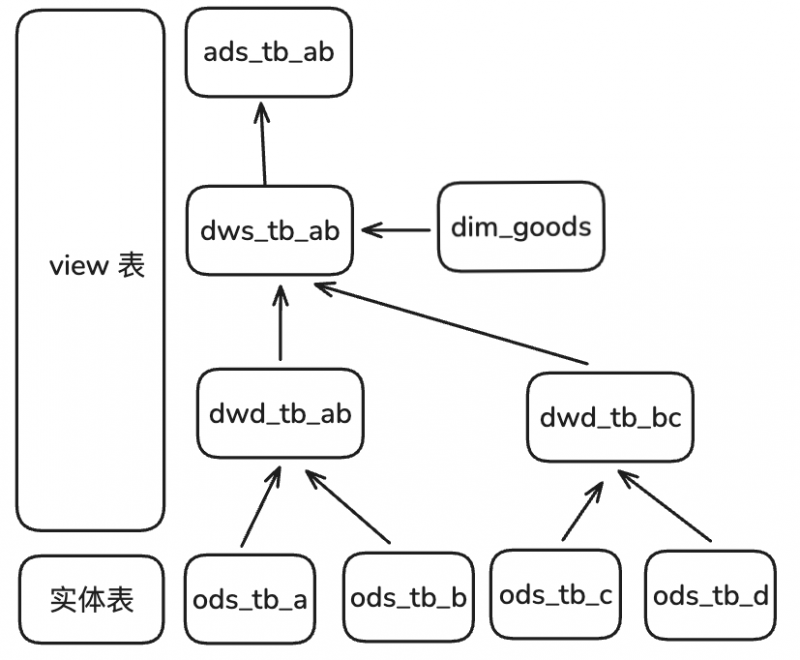
早期建模使用异步物化视图表进行建模,但是会存在延迟问题,无法使用最新鲜的ods的数据,每一层的调度都存在一定的延迟可能,如果是3层,每一层是定时5分钟刷新一次,如果刚好卡上时间点,数据从ods到ads层的数据延迟最大能达到近15分钟,上层ads层的数据最大延迟时间是物化试图刷新时间可能会达到最大值才能展示数据。
针对上述情况,结合阿里云和StarRcocks分享案例,采用view sql(逻辑视图)建模为主,这么做的好处是,view table 存储的数据sql的逻辑,直接执行后会把需要进行查询的数据透传到最底层的ods层。保证数据新鲜度是自己准实时的数据,而且利用了view table 来进行了分层,这样保证了每一层只处理了自己相关的业务逻辑, 但这么处理建模逻辑活成,即会有优点,也会有缺点,主要体现如下:
1、主要优点:
view table是无状态的,view table里面只存储了DQL 查询语句,每次只需要进行相关view 表的逻辑即可,不需要关心底层的数据。按照逻辑封层,对于建模过程是非常合理的,开发成本很低。
2、主要缺点:
因为view 表没有存储数据,用户在查询view表的时候会透传到最底层的ods实体表中来扫描数据,如果ods层的基表数据量很大且没有经过加工,那么olap的速度不会得到明显提升。用户端体验不是很好。
面对上面的缺点,我们物化视图/生成列中使用解决办法帮助用户进行加速OLAP大查询
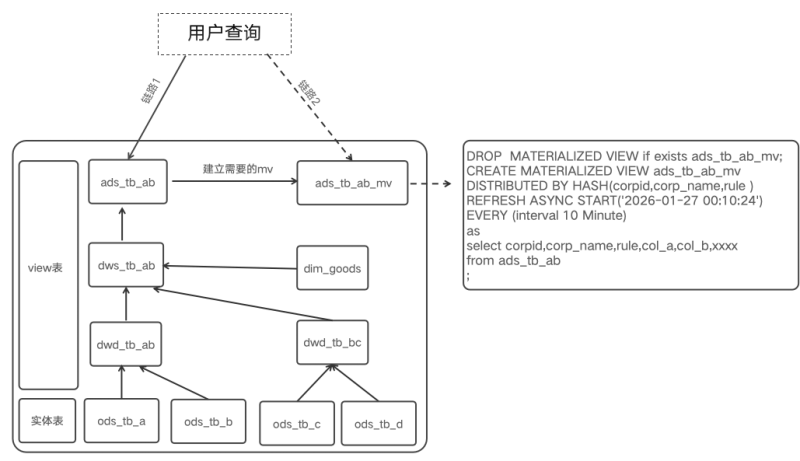
对于报表中需要透出的OLAP 表,我们可以新建一个和view table逻辑相同的物化视图来进行加速。每10分钟进行一次调度任务,这里是每次全量的异步物化视图刷新。
用户可以根据自己的实际业务情况来进行物化视图的更新方式,目前StarRocks的异步物化视图刷新主要是两种,一种是异步的全量,另一种是异步的分区增量级别刷新,分区增量刷新需要依赖基表是分区表才可以实现,如果业务表没有分区,全量的异步物化视图刷新是比较耗费内存和cpu+运行时间。
业务DB具有很多的半结构化数据,尽管StarRocks在早期就对JSON数据类型进行了优化,但是查询一个JSON中的数据远不如直接查询一个字段来的检索效率高,这时候我们采用生成列,把JSON中一些固定字段脱离出来,在不影响原有的业务逻辑,查询效率约等于查询固定字段的效率。
语法如下,可以在建表的时候创建,也可以后期增加,不影响源表的任何逻辑

查询改写
如果查询中的表达式与某个生成列的表达式匹配,则优化器会自动进行查询改写,直接读取生成列的值,这里不需要用户的任何操作,极大的方便了数据开发和数据模型的维护。

StarRocks 的异步物化视图采用了主流的基于 SPJG(select-project-join-group-by)模式透明查询改写算法。在不修改查询语句的前提下,StarRocks 可以自动将在基表上的查询改写为在物化视图上的查询。通过其中包含的预计算结果,物化视图可以帮助您显著降低计算成本,并大幅加速查询执行。
下图是StarRocks中的异步物化视图的改写逻辑,这里不仅支持内表的改写,同样支持外表的改写。对于查询走到1链路,还是2链路,对于用户是无感的,由StarRocks优化器自行判断和操作,且StarRocks保证了数据强一致性。StarRocks物化视图改写简介里有详细的介绍,这里不做过多说明。
案例参考如下:

对于外部客户数仓中,我们依然需要继续使用StarRocks作为查询引擎,查询Paimon中的ODS层的同一份数据。外部数仓中的加工处理逻辑不变,整体保证统一。
对于ODS上层的数据,因为外部数仓和内部数仓是逻辑上隔离的,但本质其都是架构上湖仓上的数仓,对于一些用户行为数据(登录、发送、埋点)等,我们会按需写入数据湖中,Maxcompute和StarRocks同样都支持写入Paimon,保持业务最小侵入,按需供给。
得益于StarRocks中强大的OLAP基因,我们内部BI基本从过去的MaxCompute 替换成StarRocks作为内部BI的OLAP数据库(支持谓词下推),而且得益于StaRocks的LakeHouse架构,我们还可以使用在StarRocks挂载Paimon的Catalog,充分利用Data cache 机制+DV表+数据预热,充分加速内部BI速度,从MaxCompute切换到StarRocks中,只要改动部分少许的兼容函数即可。基本能做到99%可替换。
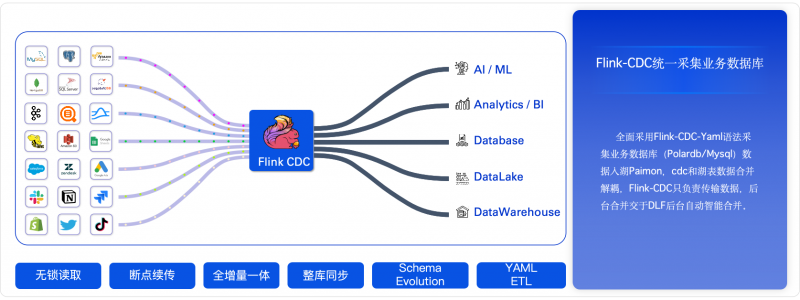
全面采用Flink-CDC-Yaml语法来采集业务DB(polardb/mysql)数据入湖Paimon中,现在支持cdc和合并解耦,Flink-CDC只负责传输数据,后台合并交于DLF后台自动智能合并,且Flink-CDC-Yaml的优点如下:
1. 更轻量化的开发逻辑、易于开发、性能更好,框架更稳定,启动模式丰富。
2. 支持整库同步+Schema Change+Sink节点复用+Flink丰富的上下游生态。
3. 支持Route,解决过去分库分表和整库同步不能复用source的问题,过去需要写两个CDAS语句
4. 支持Transform,可以在ETL的过程中增加一些必要性的字段转换。
5. 支持Exactly-once和At-least-once模式,保证数据不丢。
6. 丰富的启动方式,支持快速修补数据,包括init(全增量) 、最新点位启动、最早点位启动、时间戳、特殊点位启动、快照启动和快照数据过滤启动(社区有pr,还没合并),基本能做到最小代价来获取数据/修复数据。
7. 支持Pipeline框架并行获取历史数据,极大加速历史快照数据,支持无锁拿最新数据,不需要锁表,锁库,增量阶段全局保序,保证数据不乱。
8. 支持自动加表,符合正则匹配的新表不需要重启作业即可同步数据到sink端。
9. 未来会支持限流(社区已经有这个讨论)
10. 相比CDAS语法,算子拓扑图更简单,性能更好,CDAS语法糖中,每一个表都是一个单独的sink额外算子,作业复杂度较高。

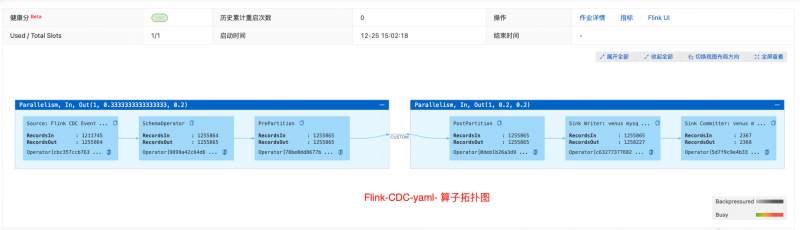
全面采用Flink作为实时计算引擎,DLF作为元数据、鉴权、数据提供,目前实时计算主要是供给内部用户使用的客户画像画像来辅助业务端来进行分析,决策,考虑未来增量计算的场景,同样可以在Flink中完成增量计算的需求,因为DLF后台的数据合并也是Flink引擎,数据入湖后的合并需要Flink来进行计算,以及未来可能考虑的Flink增量计算。
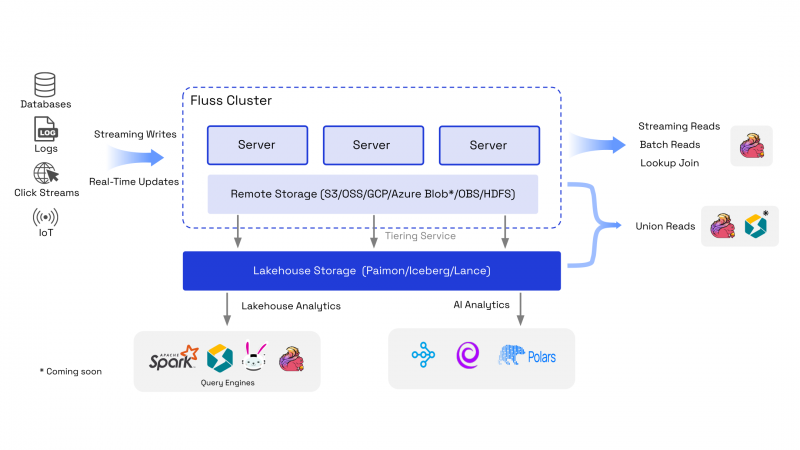
Fluss+Flink弥补湖仓数据新鲜度
Fluss目前主要承接我们内部系统的用户画像,初始阶段,我们的用户画像基础计算表是由于Mysql承接(Binlog+部分列更新能力),因为计算用户画像的流量很高,我们利用Flink 的开窗函数来进行攒批数据写入Mysql,并使用Flink 结合使用多流pk (相同主键)部分列更新能力来减少下游Mysql的压力和Flink的状态,但随着用户体量的增加,出现了性能问题。后面我们把用户画像基表迁移到了Paimon,Paimon虽然可以解决我们的性能问题,但是没办法解决Paimon的的分钟级别的数据新鲜度的问题,随着Fluss的开源,我们把目光投入到了Fluss,主要优点如:、Delta join、数据写入即可见、Union Read、湖流一体等。
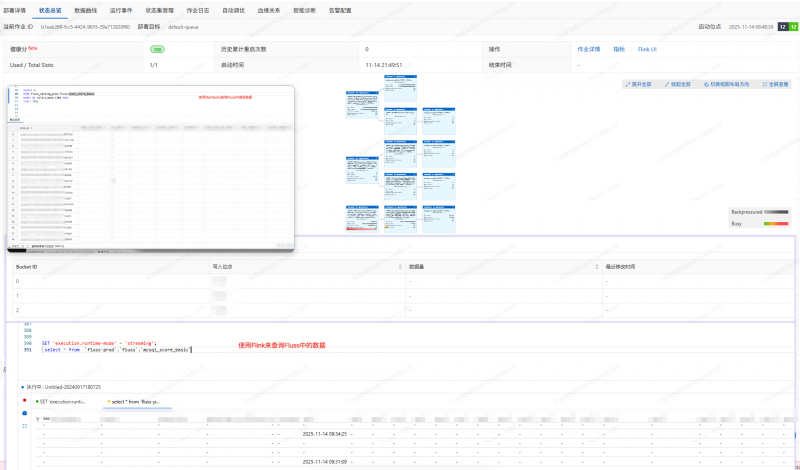
如果使用Flink来查询Fluss上的数据是一个比较慢的过程,比如我们做一些ad hoc或者排错还是比较慢,经过和云厂商沟通,现在我们可以使用阿里云上的EMR-Serverless-StarRocks来查询Fluss中的湖表的数据且支持Union Read来保证数据一致性。
Fluss作业参考:
同样Fluss也在持续推进多模态数据集成,这也是我们期待的能力点。
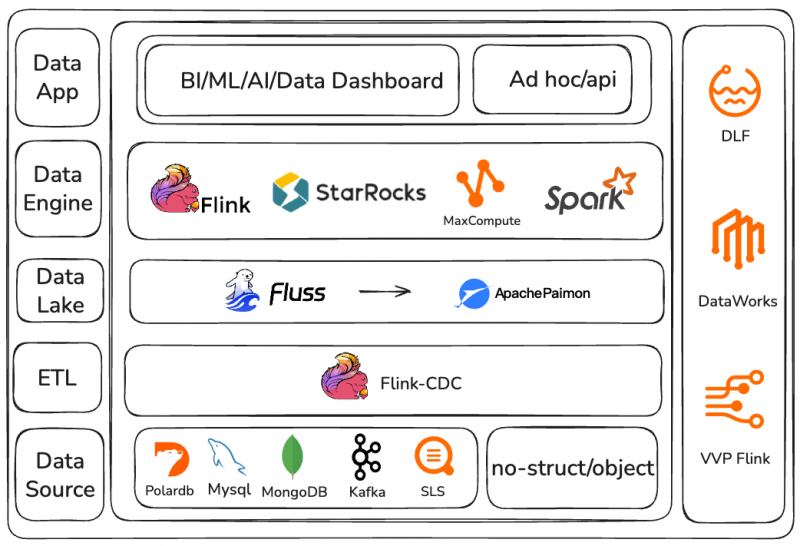
1. 数据基座
● 确定以Paimon作为数据基座,计算引擎消费Paimon中的数据,数据入湖后,其他加工依据湖上数据进行加工产出数据,最后数据回流到Paimon中。
● 确定Fluss作为作为数据湖前的中转站,作为湖流一体的能力,更符合其流存储的定位和能力,数据最终还是入湖。
2. 计算引擎
● MaxCompute作为大批量的离线计算引擎为主。
● Flink作为实时计算引擎为主,Flink-CDC作为数据入湖、入仓的ETL工具。
● 其他引擎少量为辅的主要技术栈,减少技术栈和维护成本和学习成本。
3. OLAP
● 确定以StarRocks为OLAP为主的报表引擎支撑,内部报表+外部客户报表全面采用StarRocks作为OLAP查询引擎。
4. 数据开发/元数据管理/鉴权
● 确定按照Dataworks为主要离线数据开发平台
● 实时开发采用 Ververica Platform (VVP) 实时开发平台
● DLF元数据管理为主的数据构建平台。
5. 多模态
● Lance file 作为多模态数据存储格式,同样Paimon/Fluss在持续跟进lance的推荐和集成。
1、数据永远只存储一份,不再割裂,架构简单,可替换。
2、数据的格式是开放的、计算引擎不再强绑定,做到随时可替换,数据可共享、数据不再割裂。
3、同一份数据可以随时在离线计算、实时计算、增量计算,保证计算需求的多样性和未来可持续性迭代,满足不同业务对时效、成本的全方面考虑。
4、保持其可扩展性,包括多模态数据,一样可以入湖后供需要的引擎消费
5、数据新鲜度:可以做到计算随时可切换批计算、流计算、增量计算等。
综上,我们确定了公司的内部大数据的架构图,湖仓一体已经是大数据的趋势和事实,外加DATA+AI的场景,我们在底层存储层选择了更开放的湖格式,这样湖上的数据不和任何计算引擎进行绑定,业务端按照其数据协议读取数据数据即可;数据存储一份,解决过去数据即需要存储在A有需要存储在B的痛点,数据存储成本直线下降;技术栈统一,方便后期的开发和维护。更利于大数据的长期发展。
1. MaxCompute直拉DLF3的数据,有些谓词下推,下推的不理想,导致会获取全量数据再过滤出来。
2. MaxCompute直拉DLF3的数据过程中,有些表拆分的mapper的数量不够理想,导致拉取DLF上数据慢了点(已反馈)。
3. DLF 的对于Maxcompute批写入数据的合并时间不确定(1-10分钟),产品已有规划改进,对于一些Maxcompute中批作业支持写入后立刻合并。
4. Paimon和Fluss的有些DDL操作必须依赖Flink,我们希望更精简化下操作。
5. DLF还不支持对管控Paimon表的消费者进行管理。
6. Flink-CDC-Yaml还不支持VVP Flink 的自动调优(在路上),防止作业OOM的时候可以自己加内存。
7. Fluss还不支持 AGG Table 和 RoaringBitmap。
8. StarRocks 目前还不支持查询Fluss中非湖表。

1. 当Fluss兼容kafka的协议后,我们会把原来cdc数据写入kafka的过程直接换成Fluss,毕竟kafka中的数据探查是一个非常困难的点,而且kafka没有schema概念,对于一些元数据转换自动化不是很理想,希望通过Fluss可以解决我们遇到的痛点。
2. Fluss结合Lance 做AI数据基座。
3、Fluss 支持 AGG Table 和 RoaringBitmap 可以为我们实时计算UV,代价更小,成本更低。
随着业务体量的增加和复杂度的提高,尤其是AI部分对于数仓模型产出的数据的需求越来越强烈,我们越来越需要资源进行隔离的硬需求或者用户独享资源,目前StarRocks中的存算分离支持计算资源的硬隔离,我们还能把OLAP和AI部分的需求(RAG、数据需求)的检索放在StarRocks中加速查询,各自业务域互不影响。开启存算分离后,数据只需要存储一份,数据合并压力减少。
增量计算一直是我们一个比较关注的点,我们希望最大化的节省成本和技术复杂度,对于一些历史数据,完全可以使用增量计算来进行代替,不是所有的数据都是需要准实时,参考SnowFlake、Hologres、Flink物化表等产品均已支持增量计算,除了Flink物化表可以做到秒级别的增量计算,数据库级别的增量计算目前还是分钟级别,但综合对比来说,Flink的物化表的成本相比在数据库层面的集成成本会偏高。我们希望在StarRocks同样做到增量计算,减少维护成本和计算,很高兴的是有看到StarRock的有这一明确的探讨和计划。
目前我们的睿人事系统部分数据是JSON数据结构结构,且JSON中的key是动态不固定,这使得解析、输出这些数据都是比较耗费资源的操作,目前StarRocks已支持Flat Json对半结构化数据进行数据列存,但目前受限于这个参数是整个实例的开启,我们更需要的是表级别的参数,目前StarRocks已进化到Flat Json V2(4.0已支持),我们将会持续跟进关注StarRocks种对于半结构化数据的能力和我们内部能实际使用的场景和能力。
社区方向,目前业界主要是半结构化数据-数据列存,variant字段类型,目前StarRocks已有pr支持;variant字段兼容的数据类型会比JSON更丰富,我们会持续跟进。
AI越来越火热,我们的业务复杂度也是在慢慢提升,随着Lance的火热,我们也思考和探索在AI的数据基座这部分也能和大数据这部分做到统一,目前paimon社区和Fluss已经开始集成lance,这样对我们的架构和技术栈的侵入是最小的,等后续dlf和Fluss集成后,我们依然参考可以使用现有的架构和技术完成DATA+AI的能力。
由衷的感谢阿里云DLF、VVR-Flink、VVR-Flink-CDC、EMR-StarRocks、Fluss、MaxCompute、DataWorks、StarRocks社区等团队在本次实践过程中提供的帮助和协作。
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
上一篇:
资讯频道 2026-02-05 18:32
资讯频道 2026-02-05 18:29

资讯频道 2026-02-05 18:25
资讯频道 2026-02-05 18:13

热点 2026-02-05 17:59